Learning to Program with the Wizard Book: First Pass

— a Report
Abstract
In this report I first detail the journey of my first pass through SICP in three parts, from piqued interest to conclusion (with a brief analysis of the data I gathered underway). Following that, I reflect on my learning and the contents and approach of SICP before concluding that SICP is fantastic. I have a repo of my solutions here.
Journey
Arousal
It was probably in the wee months of 2017 that I chanced across Paul Graham’s essays (and paid them attention). Why Nerds are Unpopular was the first essay I chanced across. Good thing it interested me. I also agreed with it — I didn’t care enough about popularity during high school to do any optimization towards it. And since Graham had written at least one good essay, I decided to check out the other ones: turned out, I enjoyed most of them! They were real essays — attempts at exploration, so to say — and they were about a mixture of nerdhood, culture, startups and computing. Perfect! All topics I care about: I’m a nerd; I am, without digressing deeply into culture and politics, fairly convinced contemporary society is utterly bollocks; presume I’ll have to go the startup route to avoid open offices and Java; self-explanatory.
So the essays were interesting: I disagreed with some. Others had me nodding along. And some I pondered for days. But I returned to one particular essay time and time again: Beating The Averages. The fundamental argument in it being that programming languages have a partial order in terms of power. Which makes sense, since otherwise there would be no reason for the multitude of languages. (Not even if analyzed from the angle of programming languages as thinking tools: if they’re all equally powerful, then there would be no reason to prefer any of the thinking tools above any other for any given task.) But the essay also argues that Lisp is one of the most powerful languages in existence. (Reading around in other places, it seems that the cluster around the top possibly also includes Smalltalk and ML.)
But Smalltalk’s object-oriented, and I was still annoyed at the obligatory OOP Java course at the university. And ML seemed somewhat hyped, and I had come to associate hype with JS frameworks-of-the-month. And besides, Paul Graham’s constant mentions of macros intrigued me. Metaprogramming? How could I resist something as fun-sounding as that! Besides, apparently this Scheme thing made you learn the programming aspects by stripping away syntax, giving the principles room to shine instead. I was sold! After all, Java has a lot of syntax, and programming in Java during the OOP course had felt like pure friction. Certainly, there were other things that irked me too, but the syntax correlation seemed worthy of investigation on its own.
Having decided to learn Lisp, the next step was to figure out what learning materials to use. Graham’s On Lisp was tempting, since it was specifically writ to teach metaprogramming. But to properly work through a “comprehensive study of advanced Lisp techniques” probably required a basic foundation to build atop. I steered clear of Let Over Lambda and Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp for the same reason. The Little Schemer series, while they looked interesting, seemed too focused on specific learning areas than what I was looking for. And I didn’t even consider any books with “gentle” or “practical” in the title, associating them with the kind mocked here. But two books kept popping up again and again in my search for learning materials, both of which just happened to use Scheme variants for teaching purposes while being general programming introductions.
Those books were Structure and Interpretation of Computer Programs and How to Design Programs. Quoting from Norvig: SICP “is probably the best introduction to computer science, and it does teach programming as a way of understanding the computer science” while HTDP “is one of the best books on how to actually design programs in an elegant and functional way.” The rationale behind HTDP seems to be fixing some SICP’s perceived shortcomings: the use of mathematics and (electrical) engineering examples in SICP, requiring domain knowledge outside of the computing field; and that SICP doesn’t state the principles of program design explicitly. In fact, reading about SICP on various discussion sites, it seemed like the mathematics and engineering examples were, indeed, a common source of complaint.
So, under the assumption that the complaints about the math were simply the usual math phobia… I decided to go with SICP. The fact that SICP promised an introduction to computer science also enticed me, since I had been disappointed with the lack of theory at the university. Two birds with one stone!
Distraction
It’s peculiar how, even after deciding on something, it’s still so easy to delay it. Did I consciously decide to postpone starting SICP until after the exam period? Or did it “just happen”? Or did it really take me months to decide that I would work through SICP? I don’t remember, but those three seem the only available options, none of which seem particularly flattering. But whatever the case, I started working through SICP on the third of June 2017. I read from the start of the book to ch. 1.1.6, inclusive, and did two exercises. That took me an hour. And it’s all I did on that first day. On the fifth of June I watched the first two lectures from the 1986 recordings of SICP. And after Abelson’s short talk about the essence of computer science, I already loved SICP: “On some absolute scale of things, we probably know less about the essence of computer science than the ancient Egyptians really knew about geometry.”
The exercises varied in difficulty, but I noted that many of them were pretty difficult — in the real way of requiring serious thought, not in the often misunderstood way of simply requiring a lot of tedious work. And there was quite a bit of math in the exercises as well. I think I peeked ahead to the later chapters and saw that a lot of the math was in chapter one, though. Partly to have something of substance to base the exercises around, I imagine, to better demonstrate various techniques and aspects.
Anyhow, I kept at it, working through SICP for a couple of hours almost every day. Until the 16th of June, at which point I went on vacation with my family. And then, during the summer holidays, I ended up in old patterns of video-game playing. So instead of spending the holidays SICPing it up, as planned, I threw them away on video games. Alas! Maybe I’ll write a piece on personal responsibility in the future. Suffice to say for now that while not a complete waste of time, I wasted a lot of time nonetheless. (I stopped playing video games again at some point during the autumn.)
So the start in June turned out to be a false start. But as the university started up again my annoyances with the university and the student norm flared up again as well. I might well write a piece on that too. But the end result of that annoyance was that I remembered how interesting I had found the start of SICP — and started over again.
Satisfaction
Between the 13th of September 2017 and the 4th of July 2018, inclusive, I spent 179.3 hours working my way through SICP, including watching all the 1986 video lectures. I failed 33 of the exercises, ditched 7 exercises as “research problems” or “gigantic”, and skipped 14 exercises (and then never returned to them) for various reasons. This means that I have, to my own satisfaction, completed 302 exercises out of 356, and attempted 335 of them.
I think I was fairly stern regarding failed exercises: generally, if I checked any online answers before finishing the exercise (which I did a few times out of frustration), that counted as a failure even if I was firmly on the right track, and if I checked my answer and discovered some significant error, that also counted as a failure. After failures I simply noted them down and then continued with the book, creating a list of presumably harder exercises as I went along. (Though, I imagine it’s possible that I was sometimes too tired to rigorously apply my filter.) The list of failed exercises will be useful for when I do a second pass through the book, since I can then work my way through the failed exercises, the exercises marked for repetition, the skipped exercises and (maybe) the larger exercises — in other words, applying interleaved learning to the difficulter exercises.
I want to stress that the numbers in the previous paragraph are not approximate. While some errors might have snuck in… I have nonetheless kept track of my SICP studies in a spreadsheet. If you want to see the log of working hours and when I did what, you’ll have to check out the spreadsheet itself. Here’s the not-completed exercises:
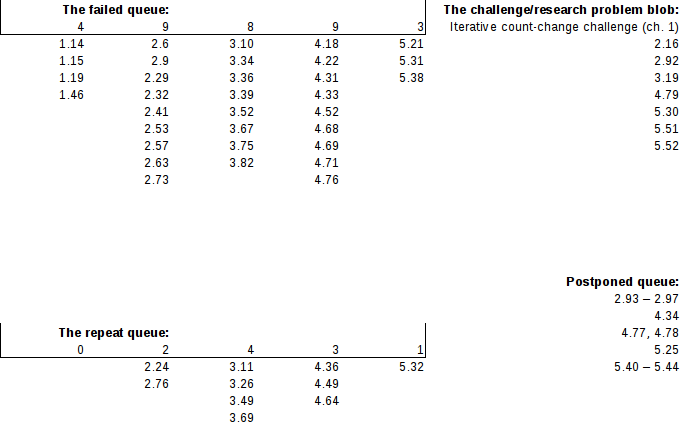
The ‘queues’ are probably ‘blobs’ too.
As a few closing words in this section, I’ll note that I found Eli Bendersky’s website, Bill the lizard, the wizardbook blog and the community scheme wiki very useful both for checking answers and comparing different approaches. Furthermore, 302 out of 356 completed exercises means that I’ve succeeded at 84% of SICP on the first pass through, and 302 out of 335 attempted exercising gives a 90% attempted exercise success rate, both of which I find satisfactory. As a fun tidbit, the the data also implies I spent an average of (179.3 hours total – 21.6 hours watching lectures) / 335 attempted exercises ≈ 28 minutes reading for and attempting each exercise.
Reflection
I have learnt a ton. In fact, I think I have learnt more from SICP than I learnt about programming and computer science during the first two years at university. I don’t want to digress into talking at length about universities at the moment, but will note that I’m fairly confident I spent more than 199 hours worth of study over the first two years at the university, giving SICP a higher ROI. (But perhaps those two years positioned me so that I could effectively learn from SICP?…) Though, one thing I didn’t learn from SICP is metaprogramming — macros aren’t covered! At least not directly… I’ll resume this thread in a bit.
Reflecting on the different SICP chapters
How far did I have to go into SICP before encountering new material? Well, the first chapter. While the comparison between programming and sorcery was interesting, seeing the three mechanisms for controlling complexity explicitly stated was genuinely new. What are the language’s primitive expressions? What are the means of combination? And what are the means of abstraction? These mechanisms are useful later on in the book too, as the book introduces other languages than Scheme, and will doubtlessly be useful in the future as I learn and/or make new languages. The difference between procedures and processes, also discussed in the first chapter? New to me. Higher-order procedures? Also new.
Chapter two focuses on data structures, mostly built around everyone’s favourite Lispy linked lists. Highlights include: the presentation of programs as multi-layer abstraction cakes with abstraction barriers between the different layers (stratified design); a meditation upon what data is by making procedures that implement the behaviour we expect from a data type, such as “purely procedural” pairs and Church numerals; the closure property (from abstract algebra) so that the results of applying the means of combination can be combined using the same means, e.g. lists of lists (of lists …); playing around with sequences and “typical” functional functions like filter, map, accumulate, etc; generic operations and data-directed programming, giving a first introduction to dispatching on data types; a section on the representation of sets which gave me more of an intuitive understanding of the analysis of algorithms (though I think my math skills currently hold me back from good application); and two very fun example programs, namely a symbolic differentiator and a picture language.
Having covered procedures in chapter one and data structures in chapter two, chapter three introduces state. This leads to the forced introduction of the “environment model of computation” compared with the “substitution model” from the first chapter, as time becomes part of the program. Following the presentation of the new evaluation model, SICP then presents the creation of simple objects through “encapsulating” local state in frames in the environment, followed by presenting mutable data structures. I enjoyed how the authors discussed the costs and benefits of introducing assignment/state/time into programs, which also set a nice foundation for their (brief) discussion of concurrency: from sequential actions in time to, well, concurrent ones. Then, after having detailed how time enters in a “typical” program with mutable state… SICP turns time on its head by introducing streams as a different paradigm for how time could enter a system. (And as infinite data structures — infinite data structures are also fun!)
It was at that point, when streams were introduced, that I told a friend that SICP tended to teach something in-depth, and then invert it all to teach it even better. That was the experience when chapter one went from first-order functions to higher-order ones; that was the experience when chapter two showed how to construct data structures using procedures directly; that was the experience when chapter three went from time in mutable state programs to time in stream programs; and, indeed, that was the experience in chapter four when moving from the metacircular evaluator(ish) to logic programming, and in chapter five when moving from the explicit-control evaluator to compilation. As a final note on chapter three, although not labeled as examples in the book’s table of contents, it includes two delightful systems: a simulator for digital circuits, and a constraint propagator.
Chapter four concerns metalinguistic abstraction, and implements three scheme variants: a metacircular scheme, a lazy scheme and a nondeterministic scheme. The chapter also develops a logic programming language, like a mini-Prolog. The metacircular evaluator gives a new evaluation model with yet more detail than the environment model of chapter three. The evaluator is how Scheme could be interpreted. In Scheme. Which simplifies some aspects. The two Scheme variations showcase some of the utility of metacircular evaluators, as well as some of the breadth in possible programming languages (which is then broadened further by the logic programming language). Personally, I found the nondeterministic Scheme variant particularly fun: an evaluator with a built-in search mechanism! I also particularly enjoyed the exercise(s?) on the halting problem.
Finally, chapter five introduces register machines — hardware, at some level of abstraction. After designing a few simple register machines to get used to the notation, a simulator for the register machines gets presented. Then, after first detailing a few of the simplifications that are at play, SICP goes on to implement a Scheme evaluator as a register machine: the Explicit-Control Evaluator. And then, in the last subchapter, SICP gives an introduction to compilation, and the differences between interpretation and compilation… And the possible interplay! Interpreted code calling compiled code, compiled code calling interpreted code… And, in presenting the Explicit-Control evaluator, the authors give another evaluation model, this time in the form of how a possible hardware(ish) system could run Scheme programs. Chapter five also includes some interesting discussion about tail recursion. And at its conclusion, you can compile the Scheme evaluator from chapter four, run the compiled evaluator inside the Explicit-Control evaluator, which runs on the register-machine simulator, which is a Scheme program, which means it could be run by the compiled Scheme evaluator…

The Great Schemouroboros
Reflecting on the Macro Thread
As mentioned earlier, SICP doesn’t discuss macros — not beyond a single footnote, that is: “Practical Lisp systems provide a mechanism that allows a user to add new derived expressions and specify their implementation as syntactic transformations without modifying the evaluator. Such a user-defined transformation is called a macro . Although it is easy to add an elementary mechanism for defining macros, the resulting language has subtle name-conflict problems. There has been much research on mechanisms for macro definition that do not cause these difficulties. See, for example, Kohlbecker 1986, Clinger and Rees 1991, and Hanson 1991.” As syntactic transformations, macros provide a mechanism for syntactic abstraction. “A macro is just another mechanism for creating abstractions — abstraction at the syntactic level, and abstractions are by definition more concise ways of expressing underlying generalities.” In other words, macros are functions that take source code as input and return transformed source code. This means that a piece of source code is data for a macro to operate on.
So while SICP doesn’t discuss macros, and none of the evaluators implement macros, SICP does introduce some syntactic transformations as a way to implement derived expressions in the evaluators of chapter four. COND->IF, LET->COMBINATION and LETREC->LET, for example. I mention this because it seems likely that having seen basic syntactic transformations as parts of those evaluators has prepared my mind a little for, well, macros and syntactic abstraction. In addition, the evaluators necessarily also operate on (input) source code, greasing the “code as data” idea. So when I read chapters seven and eight in Practical Common Lisp, I felt like something clicked, both regarding macros and regarding a deeper understanding of the evaluators: operations on source code, touched on it in the SICP evaluators; syntactic abstraction, same; syntactic abstraction, makes sense from SICP implementing different languages with different syntax and semantics. So having been very lightly introduced to macros, they seemed… Natural. Reasonable. No doubt I’ll fuck them up a lot before I get the hang of ’em: I don’t claim expertise, I claim the most basic of understanding.
Reflecting on Languages
SICP teaches Scheme programming as it meanders along, but the book also introduces various other languages. Most obvious of those is the logic programming language of chapter four. While it shares syntax with Scheme, parentheses and prefix notation, the semantics are vastly different — those of a logic programming language. But the semantics of the nondeterministic Scheme variant and lazy Scheme variant are also different from Scheme, albeit with significant overlap. Are those variants separate languages? One of the examples in chapter two is the picture language, and it’s introduced with an analysis of its primitives, means of combination and means of abstraction: painters; operations that make new painters from old painters, e.g. by flipping or stretching; and abstraction through implementation as Scheme procedures, riding along on the power of that mean of abstraction. The register-machine simulator of chapter five accepts a kind of pseudo-assembly. But the digital circuit simulator program of chapter three also has its own primitives, means of combinations and means of abstraction (though I think I remember it too using the Scheme procedures as a mean of abstraction). Its primitives were different gates, the combinations wiring-ups of different gates to produce different chips. Does the digital circuit simulator have its own language?
Presumably… yes! A language that shares a lot with Scheme, for sure, but Scheme doesn’t come with built-in facility for simulating digital circuits. Abelson and Sussman (and Sussman?) stress on various occasions the difference between stratified design and problem decomposition. Rather than break a problem down into subproblems into subproblems until the subproblems are trivial enough to be implemented, designing a program for the specific problem, they advise building up layers of language until you have a language that is suited for the kinds of problems you’d like to deal with. One of the video lectures in particular touched nicely on this, but I can’t remember which one. In the simplest case, the language is a thin layer above list handling for semantic data structures. In the more advanced cases, well, you basically make whole new domain-specific language, presumably. Graham has an essay along these lines titled Programming Bottom-Up.
This view of largely structuring programs as languages suitable for specific problem domains intrigues me, and has intrigued me from the moment I read/heard it. Clearly, macros will be of great utility in that regards, offering easy-to-create syntactic abstractions — which make certain things easier to do than if working with purely functional abstractions. For a trivial example, consider writing an UNLESS operator that works like IF in reverse. That is, (unless predicate consequent alternative) → (if predicate alternative consequent). UNLESS, like IF, would have to be a special form, so as to not evaluate both the consequent and alternative… But new special forms can’t be made through functional abstractions! Whoops! Syntactic abstractions to the rescue. As pertains basic syntax, I find that I enjoy Lisp’s a lot. While it took some effort to get used to, I now find the prefix and parentheses style elegant. Separating operators from arguments is trivial compared with Algol-style syntax. Thinking back to when I first learnt programming, I found the number of symbols in use an extra cognitive load: What was the difference between [], {} and () again? Where do the semicolons go? Perhaps it’s easier to learn the underlying programming aspects through Scheme than through struggling through a course on syntax, and thereby providing hooks for the syntax to have meaning later on?
Reflecting on the Teaching Style
I have just mentioned how Scheme seems a good learning language to me, and earlier I touched on the gradually deepening mental evaluation models as the book progresses. It’s funny that the programs in the book are bottom-up-ish through stratified design, while the teaching is top-down-ish, working from functional programming through imperative programming through evaluators down to simulated hardware. One big difference between the book and other introductory programming books I had touched when I started reading SICP was that SICP had example programs galore. Substantial example programs. And the exercises were good, often involving analyzing, extending or modifying the example programs. I found this a very learnsome approach, particularly compared with the “standard” approach of presenting programming techniques in as isolated a manner as possible, and then having exercises consisting of extremely trivial applications. In a way, SICP, in providing so many program examples, is analogous to the common advice given to aspiring writers: “Read!”
Furthermore, the authors also make explicit various mental frameworks I haven’t seen in other places: e.g. the three mechanisms for controlling complexity, or the increasingly sophisticated evaluation models culminating in programs as models. The growing arsenal of techniques and aspects at the reader’s behest is also reinforced through examples reoccurring throughout the book: Newton’s method figures in the first and last chapter. The streams of chapter three make a comeback in chapter four. The sets of chapter two reappear later on as well. Revisiting earlier ideas and approaches helped tie the book together into a coherent whole. In terms of deliberate practice, the revisiting providing a form of rework seems like an excellent real learning device.
Conclusion
SICP doesn’t shy away from philosophical discussion. It raises issues regarding time. It discusses the notion of “sameness” or “equality”. It brings up how “a variety of inadequate ontological theories have been embodied in a plethora of correspondingly inadequate programming languages”. Rather than spend all its time on programming techniques, SICP raises the question of what the essence of computer science is. Is computer science a science? Is it about computers? During my search for learning materials, I read some complaints about the time SICP spent philosophizing. I personally found the time spent philosophizing well spent, as it provided further perspective and helped me ponder things more deeply — even if the conclusion of some piece of philosophizing was that we don’t really know the answer or have an obviously decent candidate.
Finally, I’d like to mention that the way I program has changed immensely compared with how I programmed before I started on SICP. And one way I acutely notice that is in the level of abstraction I think in. Prior to SICP the most complex program I had written (and not alone) was a Pong game in C++, so I was obviously no expert going in. Thinking back, I used to program at a level of abstraction of roughly the next line of code. Did I need a function? Well, then. Time to define the function. And the parametres. And then, what is the function supposed to do? One line at a time. Maybe initialize some variables. Then do some simple operations that prepare for some other operations. And so forth. After SICP, however, as I noticed when working on a web app, I thought naturally about manipulations of data structures. Simple function generators. Whole functions at a time. I can lift my gaze from the ground and see at least part-way to the horizon. Realizing I could now reason about programs at a higher level was a pleasant surprise, and seems to tantalizingly offer even higher levels of thought with further practice and study.
